Training AlphaZero for 700,000 steps. Elo ratings were computed
Por um escritor misterioso
Descrição

Generally capable agents emerge from open-ended play - Google DeepMind

AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Training AlphaZero for 700,000 steps. Elo ratings were computed from

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity
AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela-zero · GitHub
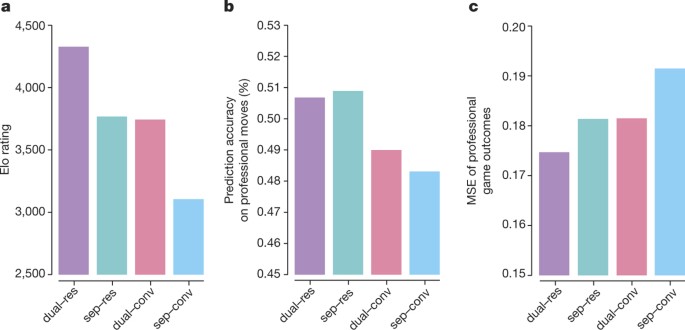
Mastering the game of Go without human knowledge
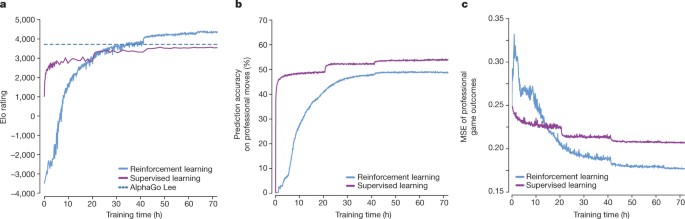
Mastering the game of Go without human knowledge
de
por adulto (o preço varia de acordo com o tamanho do grupo)